
Rebel100™
Scaling Frontier LLMs with UCIe-Advanced & HBM3E
Powering AI Inference Efficiently and at Scale

Deploy anywhere, without compromise. Run fully on-prem in existing air-cooled data centers with full control over data, security, and operations.

Built for seamless integration. Works with open-source frameworks and industry-standard tools — no vendor lock-in, no new skills required.

Designed for real-world AI economics. Delivers strong performance-per-watt, optimized for large-scale inference workloads.

Proven at scale. Deployed across enterprise and government environments, supporting real-world AI workloads.

Designed to deliver high performance with strong energy efficiency, reducing power consumption and operational costs for large-scale inference deployments.

Up to 2 PFLOPS FP8 performance with 8 RebelCards™ per server, each powered by a Rebel100™ chip with advanced chiplet architecture and high-bandwidth memory.

Supports a wide range of AI workloads, including large language models, MoE architectures, and multimodal applications across language, vision, and speech.

Integrated with leading open-source frameworks such as vLLM, PyTorch, and Triton, enabling seamless deployment and optimized distributed inference.



* Theoretical maximum power consumption based on specifications. Actual power consumption will not exceed 7 kW, typically hovering around 4-6kW at most under practical workloads.
Scaling Frontier LLMs with UCIe-Advanced & HBM3E

Powering AI Inference Efficiently and at Scale
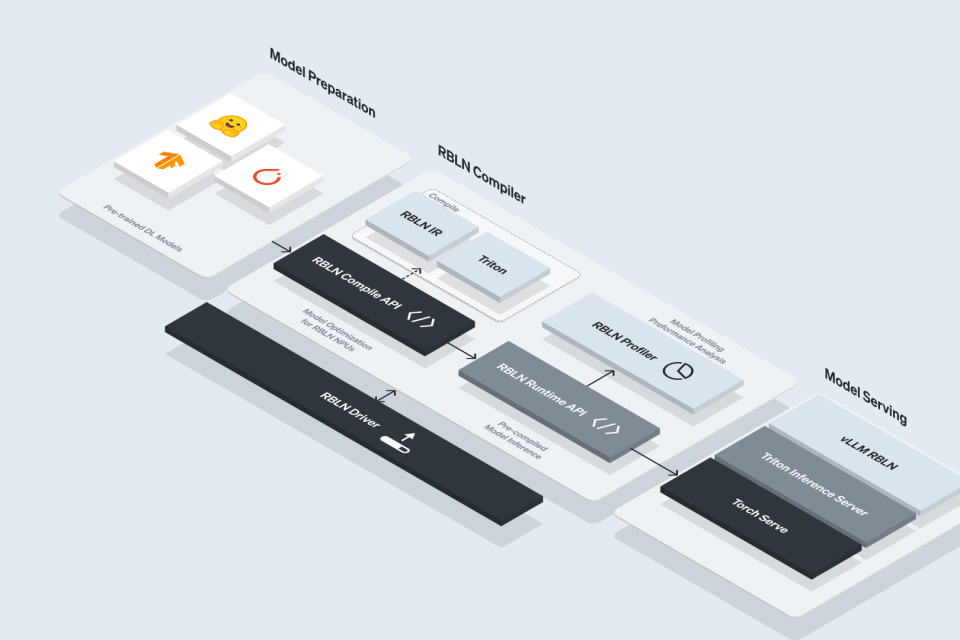
Built for Developers Who Scale AI

High-Performance AI Cluster with
Rack-to-Rack Scalability and RDMA Networking

Large-Scale AI Inference
Starts with a Single Server