Rebellions Delving Deeper into the AI Ecosystem
Rebellions has experienced significant growth in the past four years as a result of our unwavering commitment to revolutionizing AI compute. Our team of talented engineers has been tirelessly dedicated to creating AI inference that is not only fast and efficient, but also sustainable, making AI technology more accessible on a larger scale. This dedication has led to the development of our highly acclaimed AI accelerator chips: ION™, ATOM™, and REBEL.
In line with the rapid advancements in AI, one of our recent achievements at Rebellions has been the successful support of large language models (LLMs) through our multi-card configuration under the Rebellions Scalable Design (RSD). Throughout this process, we have always prioritized providing a seamless experience for developers and ensuring a smooth transition for users of different frameworks.
Our commitment to delivering the best developer experience is evident in our roadmap. We are thrilled to announce some of our ongoing progress, including our native support for PyTorch 2.0 and optimizations for serving LLMs.
Native PyTorch 2.0 Support
As a dedicated member of the AI/ML ecosystem, Rebellions consistently stays updated on the latest advancements in popular frameworks. Keeping in line with this commitment, a seamless PyTorch experience for Rebellions’ RBLN SDK users has always been a top priority. This allows its thriving developer community to effortlessly harness the power of Rebellions’ technology.
PyTorch has solidified its position as the go-to framework in the AI/ML community due to its Pythonic style, versatility, and performance. It is highly regarded for both academic research and industrial applications.
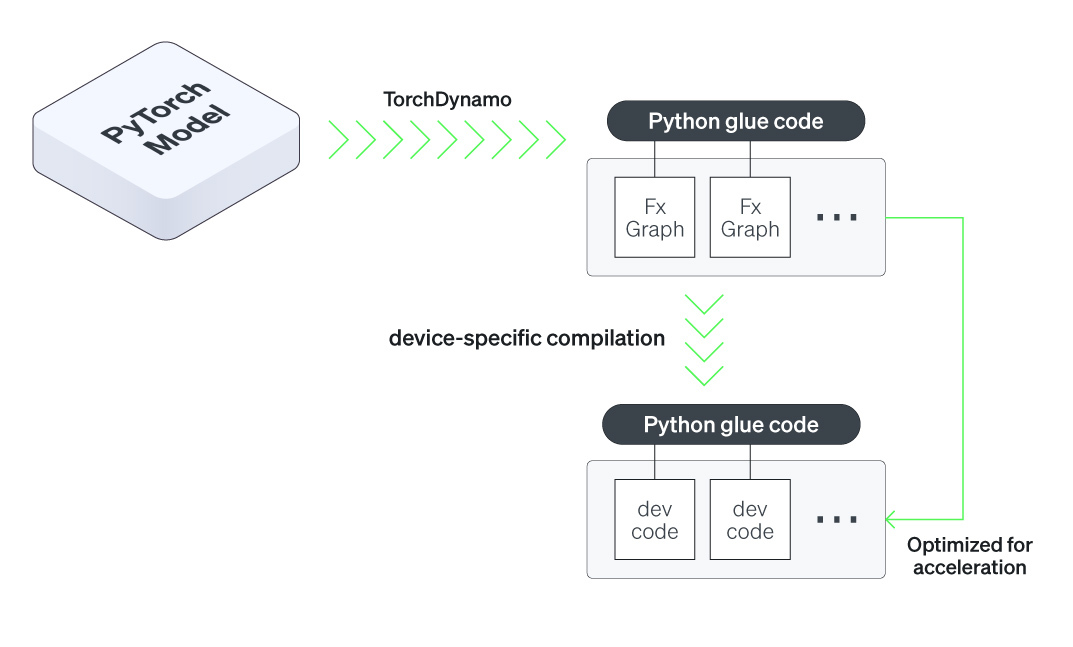
PyTorch 2.0, which was launched in 2023, represents a significant step forward in terms of compiler-level model optimization. One standout feature is torch.compile, a dynamic compilation framework that enhances the performance of PyTorch models during both training and inference. This is made possible by the integration of cutting-edge technologies such as TorchDynamo, AOTAutograd, PrimTorch, and TorchInductor. With its versatility, the new PyTorch version offers a unified interface that supports various AI accelerators.
In recognition of these industry milestones, Rebellions’ Software Team released the initial integration with torch.compile. The integration of Rebellions’ SDK into PyTorch 2.0 enables developers to seamlessly harness the full performance of Rebellions’ AI accelerator line-ups, just like they would with other devices such as GPUs.
ResNet50 compilation in PyTorch using RBLN backend

To find out more details about our PyTorch implementation, you can check out our documentation RBLN SDK User Guide.
Optimizing LLM Serving with vLLM Support
At Rebellions, we are fully dedicated to enhancing the LLM serving experience.
The growing interest in LLM serving – the process of deploying and serving LLMs to handle user requests – has led to the emergence of a vibrant ecosystem in which participants with different capabilities join together to provide integrated LLM solutions to application developers. The key ingredients include optimized and scalable models, API endpoints, and orchestration for seamless integration.
This trend presents an opportunity for emerging AI accelerator companies like Rebellions, as it opens up possibilities for integrations and partnerships. The increasing demand for LLM serving and AI accelerators that specialize in LLM inference will contribute to the growth of the ecosystem. To position ourselves effectively within this ecosystem, Rebellions has been focusing on optimizing LLMs.
To start, our Software Team has implemented continuous batching for LLM serving in our chip ATOM™, in full integration with the well-known open-source serving framework vLLM. This optimization is currently being prepared for commercial use in API services in collaboration with industry partners.
As next steps, we are enabling other core vLLM-based technologies like PagedAttention and FlashAttention to further optimize memory usage and latency, which is essential in an extra long sequence of LLM services. These optimization techniques, and many more, will be made available as part of a comprehensive LLM optimization solution for PyTorch.
Stay Tuned!
Driven by a profound commitment to the AI/ML ecosystem, Rebellions has consistently prioritized the usability and convenience of developers within the community. We firmly believe that our support for PyTorch 2.0, alongside cutting-edge advancements like vLLM, will elevate the development experience to new heights, ultimately benefiting the entire ecosystem.






