
ATOM™-Max Server
Large-Scale AI Inference
Starts with a Single Server
Boosted Performance for Large-Scale Inference
ATOM™-Max is the best in-class AI accelerator engineered for data centers and enterprises, delivering an impressive performance boost for large-scale AI inference workloads. ATOM™-Max achieves 128 TFLOPS (FP16) and up to 512 TOPS (INT8) / 1024 TOPS (INT4), with a bandwidth of 1024GB/s, ensuring maximum throughput for demanding applications.

Exceptional AI compute with a substantial bandwidth boost

Seamless and fast data exchange using PCIe Gen5 x16, reducing latency and enhancing scalability

Specifically designed to meet the needs of large-scale enterprises and AI-driven infrastructures
Large-Scale AI Inference
Starts with a Single Server

High-Performance AI Cluster with
Rack-to-Rack Scalability and RDMA Networking

Scaling Frontier LLMs with UCIe-Advanced & HBM3E
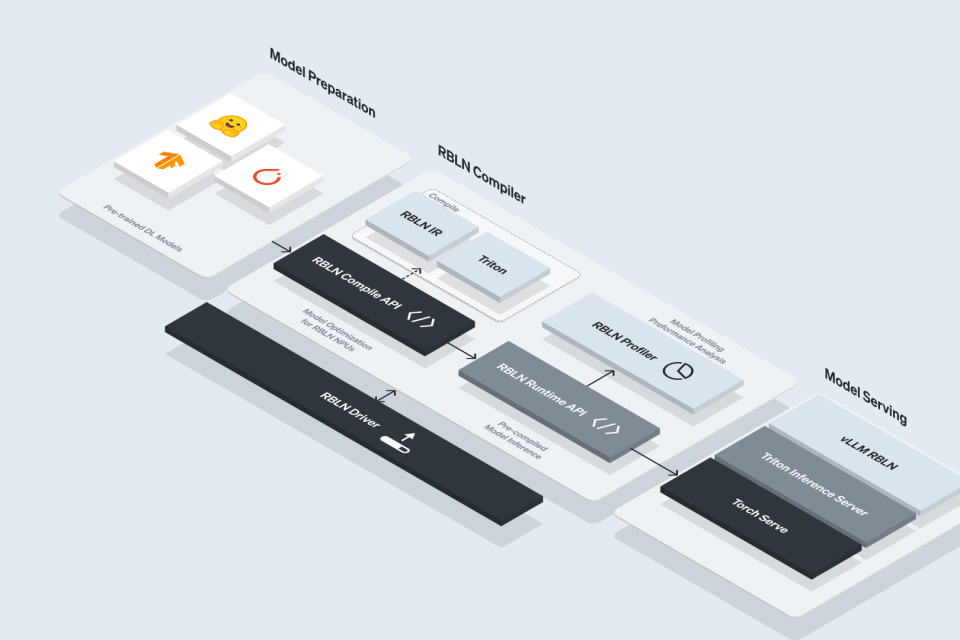
Built for Developers Who Scale AI