
RebelServer™
Powering AI Inference Efficiently and at Scale
High Utilization, Low Power, Proven at Rack Scale.
Built to serve frontier LLMs with high utilization and low power.
Powered by unified mixed precision cores, predictive DMA, and UCIe interconnect.
Rack-scale performance. Modular flexibility. Ready for deployment.

Rebel100™ executes FP8 and FP16 in a single, mixed-precision pipeline—no need for separate blocks or recompiled kernels. This delivers 2.8x higher compute density vs. ATOM™

Rebel100™ uses a predictive, software-controlled DMA engine tightly coupled with an on-chip mesh to prefetch KV data proactively. This enbales 2.7TB/s effective bandwidth and reduces token-level latency in 32K+ context LLMs.

Rebel100™ extends a full-chip mesh over UCIe-Advanced interconnects, offering 1TB/s per channel bi-directional bandwidth with just 11ns latency. Chiplets operate as one virtual die—no software changes, no I/O bottlenecks.

Rebel100™ implements hardware-accelerated, full-mesh synchronization across 256 routers. This avoids stalls in sparse or imbalanced workloads, sustaining high utilization across all chiplets and model phases.
Powering AI Inference Efficiently and at Scale
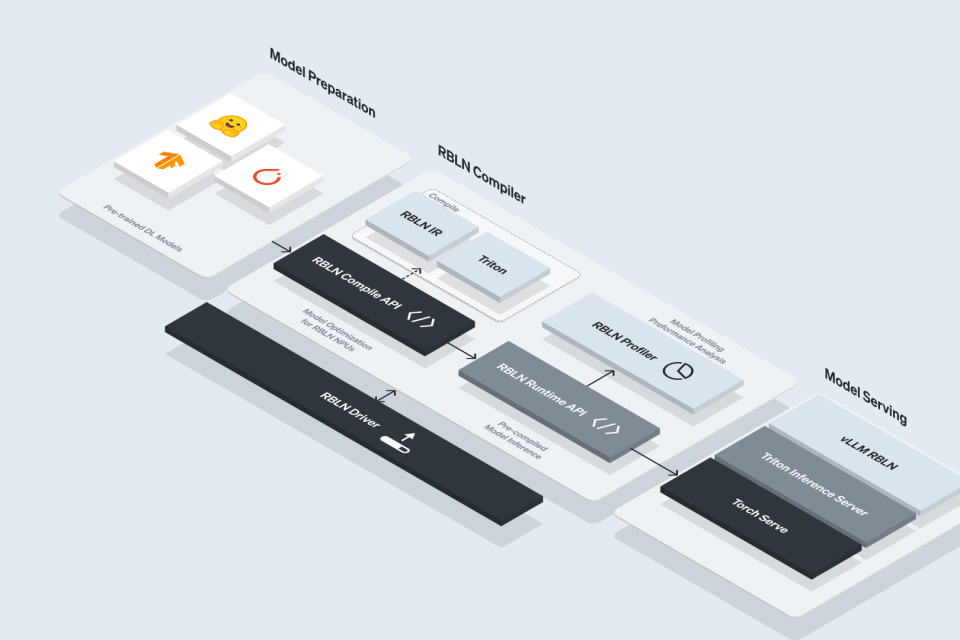
Built for Developers Who Scale AI

Large-Scale AI Inference
Starts with a Single Server

High-Performance AI Cluster with
Rack-to-Rack Scalability and RDMA Networking