
REBEL-Quad
Scaling Frontier LLMs with UCIe-Advanced & HBM3E
Deploy with Confidence from Day One.
Rebellions delivers the performance and efficiency of custom AI silicon—without compromising the software experience.
From PyTorch and vLLM to Triton, our stack offers a seamless, GPU-like workflow optimized for real-world AI inference at scale.
A GPU-class software experience designed for scalable AI inference
Purpose-built for real-world PyTorch workflows
High-throughput LLM serving with native PyTorch support
Low-level programmability meets developer-friendly design
Scaling Frontier LLMs with UCIe-Advanced & HBM3E

Large-Scale AI Inference
Starts with a Single Server

High-Performance AI Cluster with
Rack-to-Rack Scalability and RDMA Networking
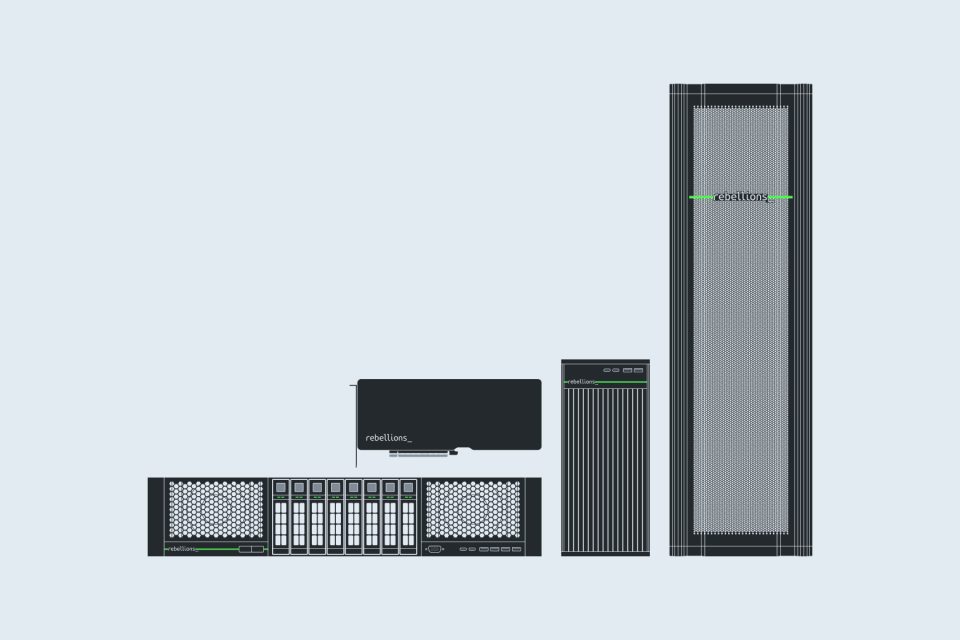
Modular Framework for Scalable Pods