
Rebel100™
Scaling Frontier LLMs with UCIe-Advanced & HBM3E
Rack-Scale AI Infrastructure with RDMA-Based High-Speed Networking
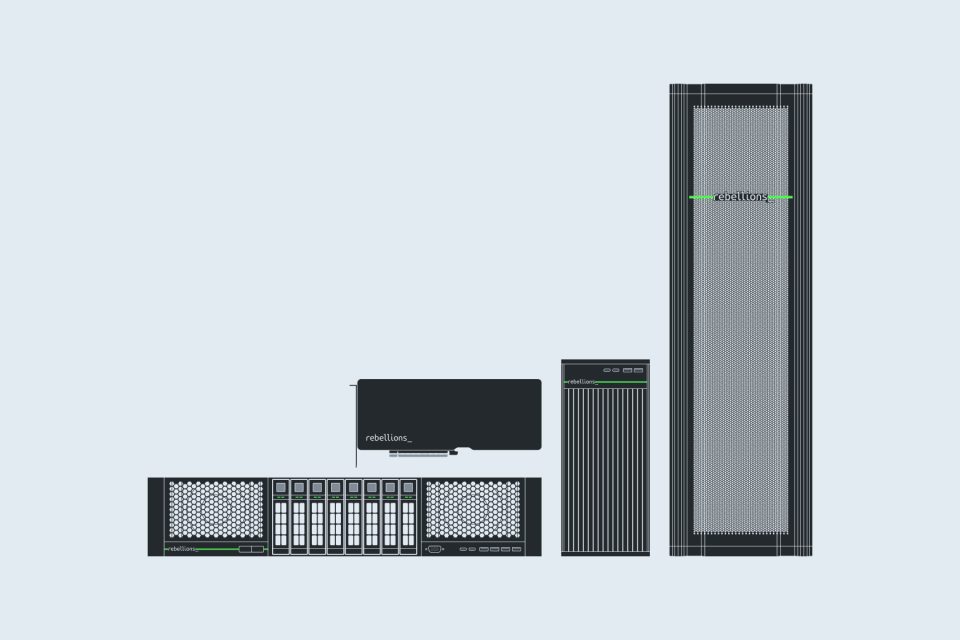
Built for large-scale AI inference, the ATOM™-Max POD is a rack-scale infrastructure designed for distributed workloads. It combines Rebellions’ AI accelerators with RDMA-based high-speed networking and a familiar software stack—all delivered as a turnkey solution. Starting from an 8-server Mini POD, the system scales flexibly to meet enterprise-level AI demands.
System Architecture
Starting from 8 Nodes
RDMA Fabric
Super-Low Latency Clustering
Per POD
Linear Scaling Performance
Turnkey Solution
Available for Deployment



From an 8-server Mini POD to a multi-rack cluster, ATOM™-Max PODs scale seamlessly via Rebellions Scalable Design (RSD), offering linear performance gains and flexible resource management as workloads grow.

ATOM™-Max servers within a POD are interconnected via 400GB/s RDMA networking, ensuring ultra-fast, low-latency distributed processing for resource-intensive AI models.

Each POD is a fully integrated infrastructure stack—combining AI accelerators, RDMA switches, and high-speed inter-node networking—ready for immediate deployment in production environments. Say goodbye to infrastructure complexity and maximize operational efficiency.

For enterprise environments, Rebellions’ Enterprise AI Solution can be integrated into the POD, delivering full-lifecycle AI serving capabilities with cost efficiency. A turnkey solution, ready to power your AI services.
Streamline enterprise-wide AI adoption—from development to deployment—with scalable AI infrastructure
Enable proactive safety monitoring on construction sites with AI-powered surveillance
Support the AI healthcare ecosystem, from personalized wellness to precision medicine
Build next-gen financial services with secure, real-time AI processing of financial data
Boost manufacturing productivity with Physical AI-powered smart factories
Power advanced telecom services and elevate customer experience with reliable large-scale AI operations.

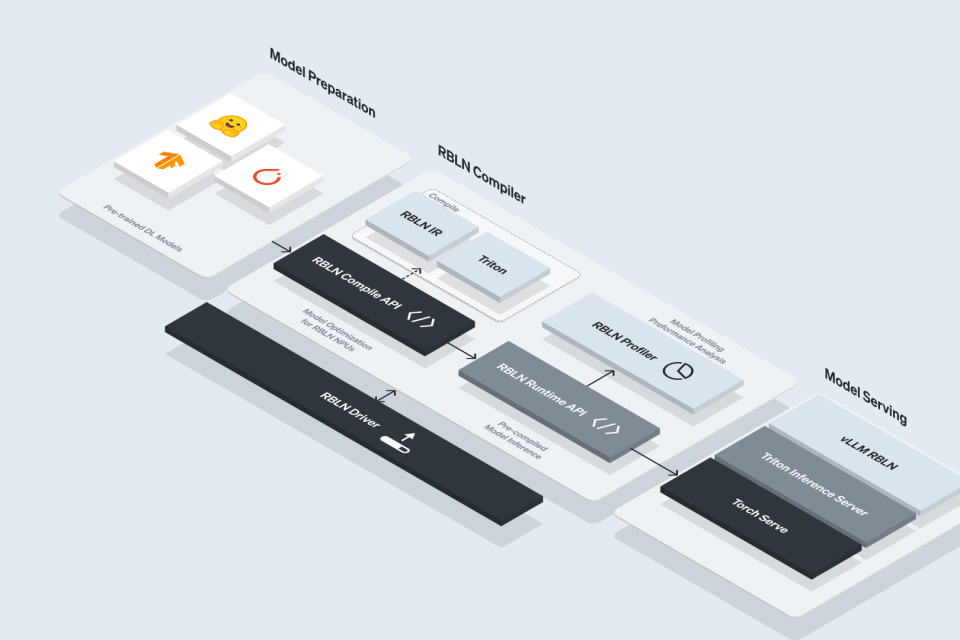
Core system software and essential tools for NPU excution
Developer tools for model and service development
300+ ready-to-use PyTorch and TensorFlow models optimized for Rebellions NPUs
Cloud-based tools for managing NPU resources at scale
Scaling Frontier LLMs with UCIe-Advanced & HBM3E

Large-Scale AI Inference
Starts with a Single Server
Built for Developers Who Scale AI
Modular Framework for Scalable Pods

Boosted Performance for Large-Scale Inference