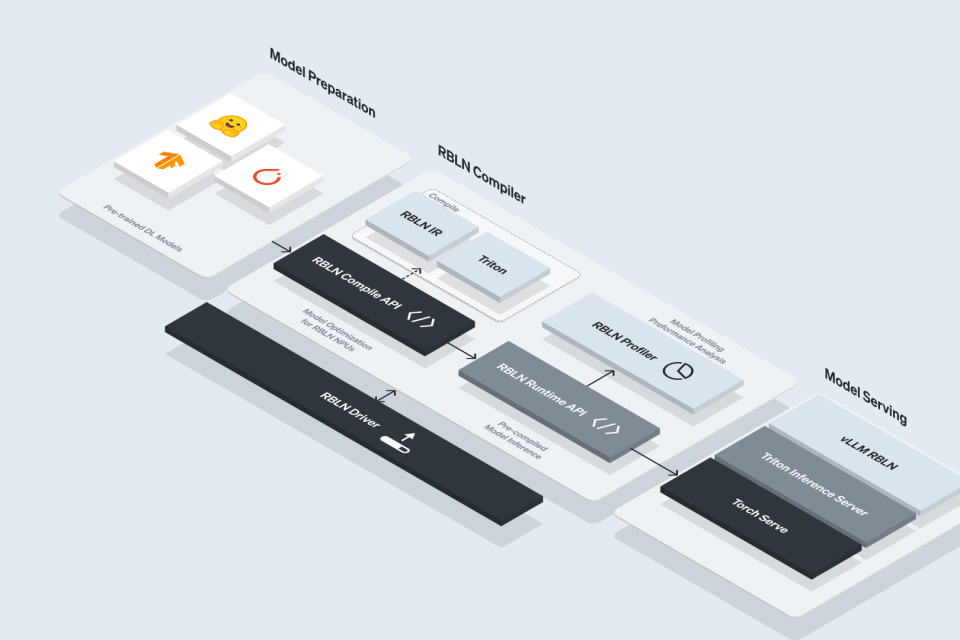
Rebellions SDK
Built for Developers Who Scale AI
High Performing Server for Large-Scale AI Inference
ATOM™-Max Server is a power-efficient, single-server solution built for large-scale AI inference. It supports up to 8 ATOM™-Max PCIe cards, enabling deployment of hundreds of AI models spanning Vision AI, LLMs, Multimodal AI, and even Physical AI workloads. Fully compatible with leading inference frameworks like vLLM, Triton, and Kubernetes, you can seamlessly transition from GPU workflows with familiar tools and guided tutorials.
Peak Performance
Maximum FP16 Performance
GDDR6 Memory
High-Capacity, High-Bandwidth Memory
Max Power Consumption 4.3kW
Built for Optimal Energy Use
Form Factor
Optimized for Data Centers
Ubuntu, RHEL, AlmaLinux, Rocky Linux
Hugging Face, PyTorch, TensorFlow, Triton
vLLM, Triton Inference Server, TorchServe, Ray Serve
Docker, OpenStack, Kubernetes

Even under heavy demand, the ATOM™-Max delivers stable, high-throughput performance—generating thousands of tokens and processing image frames per second, all from a single system.

ATOM™-Max delivers maximum AI inference performance within limited server room power budgets. Its exceptional power efficiency significantly lowers total cost of ownership (TCO) and enables a more sustainable AI infrastructure.

ATOM™-Max is compatible with popular open-source ecosystems, supporting efficient serving, flexible resource management, and monitoring through tools like vLLM, Triton Inference Server, Kubernetes, and Prometheus—so you can build full end-to-end services with ease.

Run hundreds of AI models out of the box—from LLMs and Vision AI to Multimodal AI and Physical AI. Build tailored services like chatbots, search, summarization, smart CCTV, and image generation.

No need to abandon your existing development environment. Start right away with familiar workflows (PyTorch, TensorFlow, etc.) and step-by-step tutorials.
Streamline enterprise-wide AI adoption—from development to deployment—with scalable AI infrastructure
Enable proactive safety monitoring on construction sites with AI-powered surveillance
Support the AI healthcare ecosystem, from personalized wellness to precision medicine
Build next-gen financial services with secure, real-time AI processing of financial data
Boost manufacturing productivity with Physical AI-powered smart factories
Power advanced telecom services and elevate customer experience with reliable large-scale AI operations.

Core system software and essential tools for NPU excution
Developer tools for model and service development
300+ ready-to-use PyTorch and TensorFlow models optimized for Rebellions NPUs
Built for Developers Who Scale AI

High-Performance AI Cluster with
Rack-to-Rack Scalability and RDMA Networking

Scaling Frontier LLMs with UCIe-Advanced & HBM3E
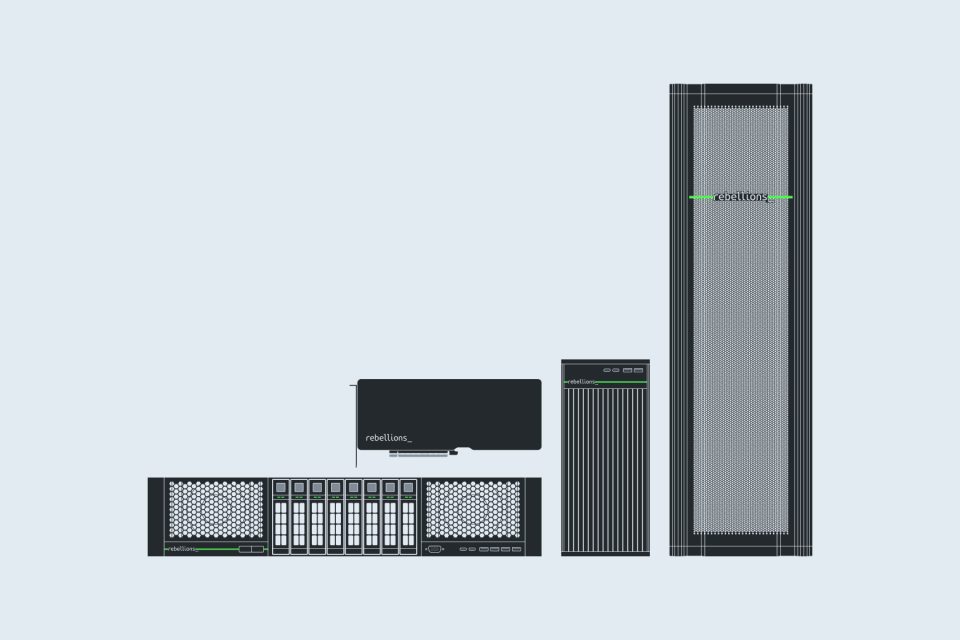
Modular Framework for Scalable Pods

Boosted Performance for Large-Scale Inference